

イントロダクション
前回は可用性とSLAの話を中心に、稼働率の計算などの話をしました。
情処の試験対策みたいな内容になっていますが、情処で勉強したことの実践編と思ってもらってもいいかもしれません。
今回は可用性の続きとして、バックアップ/リカバリや可用性を実現するための技術等についてお話していきます。
バックアップ/リカバリについて
バックアップの必要性とレベル感

バックアップは障害発生時にシステムを復旧するための最も重要な要素です。
障害発生時にしか活用しないので、運用中の注目度は低いかもしれませんが、これがないといざという時に業務継続に大きな支障をきたします。
ベンダーに復旧を依頼しても、バックアップが無いものを戻してもらうことはできません。
「バックアップは大事」だからといって毎日毎日バックアップがちゃんと取れているか逐一確認するか、というと「対象となるシステムによりけり」と言わざるを得ません。
例えば内部的にデータ保存をしないソフトであれば、インストール媒体があればリカバリには十分でしょう。
社内システムでも例えばお金に関する処理を行う受発注や財務のシステムとグループチャットのようなコミュニケーションツールでは、障害時に元に戻さなければいけない情報の正確性や復旧までに係る速度の要件は変わります。
対外的なメール、電話、ECサイトになると、サービスレベルの低下は事業継続にまで直結する影響を及ぼす可能性もあり、障害を起こさない仕組みと発生時に即時に復旧できるためのバックアップが必要になります。
「バックアップ」と聞くとどうしてもソフト的なデータのことと思いがちですが、ハード
についても故障時のスペアを保持しておくこともバックアップの一つです。
稼働している環境(稼働系)と同じハードを別に準備(待機系)して、稼働系の障害時に待機系に切り替えるような構成を「HA(High Availability)クラスタ」と呼びます。
バックアップの要件とディザスタリカバリ
バックアップに関する要件として考えられるのは以下のような内容です。
・バックアップ対象(何をバックアップするか)
・バックアップ場所(どこにバックアップするか)
・バックアップ時間(いつバックアップするか)
・世代管理(何回分のバックアップを残しておくか)
・復旧期限(障害発生から復旧までの期限)
・復旧ポイント(復旧時にどの時点の状態に戻すのか)
この中で「どこにバックアップするか」について、特に東日本大震災以降から盛んに言われるようになったのが「BCP」と「ディザスタリカバリ」です。
「BCP」とはBusinessContinuityPlanningの略で、「事業継続計画」と訳されます。災害等が発生した際に事業をいち早く継続・復旧するための計画です。
例えば大規模な地震や火災に見舞われたとして、システムの稼働場所とバックアップの保管場所が同じ場所であった場合、両方が被災してしまい復旧がかけられないことが考えられます。そうならないようにバックアップを遠隔地に保管したりする方法を「ディザスタリカバリ」と呼びます。
HAクラスタの待機系を稼働系と離れた場所に設置することもディザスタリカバリに該当します。
リカバリできないバックアップに用は無い
復旧のためのバックアップを取得していても、問題発生時にバックアップからリカバリを行おうとするとうまくいかなかったり、想定より時間がかかったりしてしまうと用をなしません。
リカバリ手順を準備する、リカバリのリハーサルを行う等のリカバリに対する準備をきちんと行うことで、復旧に係る時間、つまりMTTRを短縮することができます。
そもそも障害が起こりにくいのが一番
バックアップやリカバリの準備も重要ですが、一番いいのは「障害が起こらないこと」です。ただし障害をゼロにすることは不可能であることは前回もお話しました。
機械は必ず故障します。これは回避できないことです。
しかし機械が故障してもシステムが継続して利用することができれば、業務に影響を及ぼしません。
故障したまま使い続けるのではなく、複数の機械で分散して稼働することで、どれか一つが壊れても他の機械が稼働し続けることができます。
コンピュータのハードディスクのRAID構成などもこれに該当します。
この仕組みの一つとして「負荷分散クラスタ」と呼ばれる方法があります。
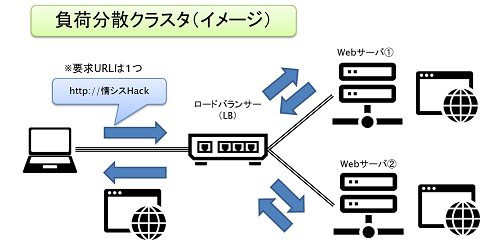
例えばWebサーバを2台構成にして、その手前にロードバランサー(LB)を置くような構成です。ユーザーからの要求(=URL)は1つで、要求を受けたLBがWebサーバの負荷状況を判断してアクセスを分散させます。
これはWebサーバが1台壊れてもアクセスが継続できる可用性の観点と、負荷分散による性能維持や、Webサーバのスケールイン・スケールアウトが容易に行えるという性能・拡張性の観点の2つの点で有効な構成です。
可用性とクラウドサービス
可用性がサービスとして提供される

大規模なシステムであればクラスタ構成やディザスタリカバリの検討が必要ですが、全てのシステムにこれらを準備することは困難です。
クラスタ構成は複数台のハードウェアを要する場合が多く、機器の調達が単純に倍以上に膨らみます。また導入後の運用保守の手間も増えてしまいます。
これらの問題を解消する手立てとしてクラウドサービスの利用があります。
クラウドサービスは稼働率保障や障害時のバックアップからの復旧をサービスとして提供しているものも多く、その管理自体がサービスとして提供されているものもあります。
要は「機器の調達も運用の手間も全ておまかせ」ということができます。
また部分的なサービスとしてIaaSやPaaSのように稼働率保障やバックアップ環境のみ提供してくれるものや、クラウドバックアップのようにデータバックアップをクラウド上で行うことでディザスタリカバリを実現するような仕組みもあります。
前者の代表的なものはMicrosoftAzureやAmazonWebServices(AWS)でしょう。後者のクラウドバックアップはBarracudaBackupなどが有名です。
あとがき
ひとり情シスにとってクラウド化が重要な理由
ひとり情シスの頭を悩ます問題の一つが可用性の問題です。
いくつものサーバやシステムの運用を一人で行い、障害が起これば休日でも駆けつけ対応を行う。バックアップの状態を定期的に監視し、ストレージ容量に気を配る。
様々な日常業務の中で、これらの問題から解消される方法としてクラウドサービスの利用が挙げられます。
もちろん情シスが楽になるためだけの導入ではありません。
担当者に依存せず安定した稼働を保障してくれるサービスを少ない費用で手に入れることができるのは企業にとっても有益です。
もちろんクラウドを利用すれば万事解決なわけではありません。
ここまで説明してきた内容を理解した上で、クラウドサービスがこれらのどの部分を提供してくれるのか、それがどれくらいの効果を産むものなのかを理解したうえで、効果的に利用することが大切です。
RFI・RFP/プロジェクト管理関連の記事を纏めています。

この記事が気に入ったら
いいね!をお願いします
